
When businesses adopt large language models (LLMs), the excitement often overshadows the hard truth: not every prompt delivers reliable, safe, or even useful results. A model might generate impressive text in one scenario but fail completely in another, producing biased, incoherent, or even non-compliant outputs. This inconsistency can erode trust, create governance risks, and ultimately slow down adoption.
That’s where Prompt Template Assets (PTAs) and structured evaluations come in. By treating prompts as structured, schema-like assets, organizations gain the ability to test, compare, and govern their AI prompts just like any other critical business resource. Instead of relying on trial and error, teams can use PTAs to enforce consistency, track performance, and identify which prompt designs truly align with business goals.
In this blog, we’ll explore how IBM’s watsonx.governance framework evaluates prompts (even with external models like ChatGPT5), why the PTA structure matters, and how you can put it into practice with real examples.
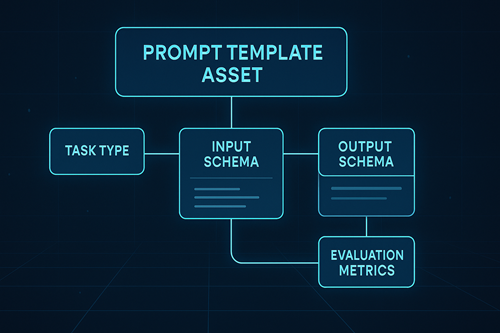
What Is a Prompt Template Asset (PTA)?
Think of a PTA as more than just a text snippet. It’s a structured asset—a kind of schema—that contains:
- Task type (summarization, classification, extraction, RAG/Q&A, etc.)
- Template text (the actual instructions given to the model)
- Variables (placeholders like
{{document}}or{{question}}) - Few-shot examples (sample inputs and ideal outputs)
- Metadata (descriptions, notes, and external model bindings)
This schema-like design ensures prompts are reusable, measurable, and governable across models and projects.
Why Evaluate Prompts?
Without evaluation, prompts can lead to:
- Hallucinations (AI making up answers)
- Toxicity or unsafe responses
- Inconsistent classifications
- Missed key information in summaries
By systematically testing prompts against metrics like faithfulness, coverage, coherence, toxicity, and accuracy, businesses can ensure their AI systems meet compliance and quality requirements.
How Evaluation Works in watsonx
- Create or import a PTA – define your prompt schema with variables and examples.
- Attach a dataset – CSV/JSON files that map variables to real inputs and reference outputs.
- Select metrics – e.g., groundedness for RAG, accuracy for classification, factuality for summaries.
- Bind to a model – run the PTA against your chosen model, including external LLMs like ChatGPT5.
- Compare results – track versions, scorecards, and dashboards to choose the most reliable prompt.
Example PTAs in Action
1. RAG / Q&A Prompt (Detached for ChatGPT5)
{
"name": "RAG QA – ChatGPT5 (Detached)",
"task_type": "rag_qa",
"template_text": "Answer the QUESTION only using the CONTEXT.\n\nCONTEXT:\n{{context}}\nQUESTION:\n{{question}}\n\nFINAL ANSWER:",
"input_variables": [
{"name": "question", "type": "string"},
{"name": "context", "type": "string"}
]
}
**Metrics: Faithfulness, Relevance, Toxicity/PII
2. Summarization Prompt
{
"name": "Summarization – ChatGPT5 (Detached)",
"task_type": "summarization",
"template_text": "Summarize the SOURCE into a concise, factual brief.\n\nSOURCE:\n{{document}}\n\nSUMMARY:"
}
**Metrics: Coherence, Coverage, Factuality, Readability3. Classification Prompt
{
"name": "Classification – ChatGPT5 (Detached)",
"task_type": "classification",
"template_text": "LABELS: {{labels}}\n\nTEXT:\n{{input_text}}\n\nChoose ONE label only."
}Sample CSV:
id,labels,input_text,reference_label
1,"positive,neutral,negative","This update fixed my issue.","positive"
2,"positive,neutral,negative","It’s okay, nothing special.","neutral"
3,"positive,neutral,negative","Worst experience so far.","negative"
**Metrics: Accuracy, F1 score, Toxicity4. Extraction Prompt
{
"name": "Extraction – ChatGPT5 (Detached)",
"task_type": "extraction",
"template_text": "Extract fields from the DOCUMENT into JSON.\n\nFIELDS:\n{{schema}}\n\nDOCUMENT:\n{{document}}"
}
**Metrics: Exact-match, JSON validity, Hallucination rate
Why This Matters For Businesses
Evaluating prompts isn’t just a technical step—it’s a business safeguard. With a structured evaluation strategy, you can:
- Improve reliability of AI responses
- Ensure compliance with governance requirements
- Reduce risks from hallucinations or unsafe outputs
- Save time and costs by identifying the best-performing prompts early
Final Thoughts
As enterprises race to integrate AI, prompt evaluation will become as standard as QA testing in software. Tools like IBM’s Prompt Template Assets make prompts first-class citizens—structured, testable, and governable. Whether you’re evaluating ChatGPT5 or any other model, treating prompts this way ensures your AI isn’t just powerful, but also responsible and reliable.
References
- IBM Documentation – watsonx.governance: Evaluate prompt templates
- IBM GitHub – Watson OpenScale Samples: Evaluating prompt templates
- IBM Cloud Docs – Prompt Template Asset overview
- IBM Blog – Responsible AI with watsonx.governance
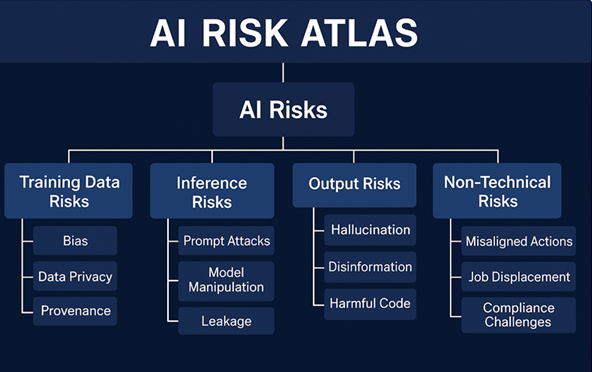
- Research Insight – IBM AI Risk Atlas (IBM, 2024): Identifying 80+ emerging AI risks, including prompt-related risks